This post is part of a collection of blog posts related to OpenShift and FreeIPA (aka idM).
- OpenShift Certificate from IPA on RHEL 8
- OpenShift authentication with IPA
- OpenShift Group Syncing with IPA (Not yet published)
- Automated Certificate Management with IPA and cert-manager (Not yet published)
Introduction
In the previous post, OpenShift Certificate from IPA on RHEL 8, I explained how to create certificates for an OpenShift cluster using FreeIPA/RHEL idM.
Now, I want to be able to log into my OpenShift cluster using my FreeIPA credentials.
OpenShift Background
OpenShift has the concept of an IdentityProvider which connects an
source of identity verification, like FreeIPA’s LDAP server, to
OpenShift.
OpenShift 4.x uses an object called an OAuth to configure identity
providers like LDAP. For OpenShift 3.x, this configuration is
similar, but locaed in /etc/origin/master/master-config.yaml
Let’s look at an example OAuth manifest:
apiVersion: config.openshift.io/v1
kind: OAuth
metadata:
name: cluster
spec:
identityProviders:
- ldap:
attributes:
email:
- mail
id:
- dn
name:
- cn
preferredUsername:
- uid
bindDN: uid=openshift,cn=sysaccounts,cn=etc,dc=private,dc=opequon,dc=net
bindPassword:
name: ldap-secret
ca:
name: opequon-custom-ca-oauth
insecure: false
url: ldaps://ipa.private.opequon.net/cn=users,cn=accounts,dc=private,dc=opequon,dc=net?uid
mappingMethod: claim
name: ldapidp
type: LDAP
This is an example of a LDAP Identity provider, there are other
flavors if desired. Notice OAuth.spec.identityProviders looks for
an array so it is possible to specify multiple providers.
We have a few things that need filled out here:
namebindDNbindPasswordcaurlattributesmappingMethod
Name
This is the display name for this IdentityProvider. When logging
on, if multiple IdentityProviders are configured, the user will see
this name to choose from. In the case of only having a single
provider, this is almost never seen.
Whatever value for name is, it should be something meaningful to the
humans that interact with this OpenShift cluster.
bindDN and bindPassword
The username and password for accessing the cluster. bindPassword
is normally sourced from a Kubernetes Secret.
ca
The certificate chain for the LDAP server. Almost every LDAP server uses a certificate signed by a non-public certificate authority (i.e. not included in the default RHEL certificate authority bundle), therefore this is almost always required.
Since FreeIPA acts as a certificate authority, this will need to be specified in the final configuration.
This is normally sourced from a ConfigMap.
url
This is the URL of the LDAP server with a query string, as defined by
RFC4516 (which
obsoletes, RFC2254).
The query string is, along with the attributes, the most important
part fo the configuration. If it is wrong, then no one can log in,
and it is significantly easier to get wrong than the other fields.
The RFCs are rather dense reading, so it’s worthwhile to break down the parts of a query string:
schema://hostname:port/base_dn?attributes?scope?filter
^ ^
+-----------------------------+
Query String
After the schema, hostname, and port, there are four fields:
base_dnattributesscopefilter
LDAP organizes it’s data into a tree-like structure. base_dn
specifies where in the tree to start searching. This can be visually
seen by tools like Apache Directory
Studio.
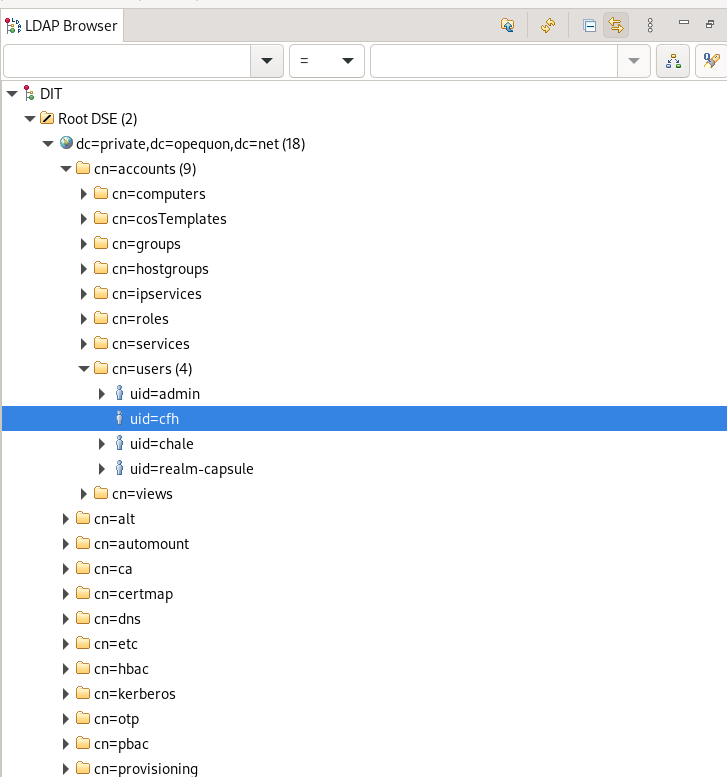
attributes specify what attributes from the found entities to return
from the search. An entity is a node on the tree that represents
something, like a user account or a group. These, of course, can have
many attributes. Some common examples are mail for e-mail address,
sn for surname, givenName, loginShell, homeDirectory.
For OpenShift, this should be a attribute that is going to be unique
to each entity in the entities returned by the query, like uid which
represents a Linux username.
Again, a tool like Apache Directory Studio can be very helpful exploring the LDAP structure.
scope determines if or how the search recurses through the tree. The options are:
baseonesub
The default is sub
base restricts itself to ONLY the base_dn and is not really useful in this situation.
one searches only the first level below the base_dn.
sub fully recurses the tree below the base_dn.
The LDAP Wiki has a good page explaining LDAP Search Scopes.
Finally, filter is an LDAP Filter that allows refinement of the
resultset even further. This is a really deep topic, but a simple
example of this is (objectclass=person). This filter will only
return entities that are of objectclass person.
If no filter is specified, then (objectclass=*) is the default.
This filter is true for all entities.
The LDAP Wiki has a lot of good examples of LDAP Queries.
With this information, we can create a URL for IPA. Fortunately, for the default install of FreeIPA, we can have a fairly simple query string.
From the example:
ldaps://ipa.private.opequon.net/cn=users,cn=accounts,dc=private,dc=opequon,dc=net?uid
This example omits some parameters. If we were to fill in the default explicitly, it would look like this:
ldaps://ipa.private.opequon.net/cn=users,cn=accounts,dc=private,dc=opequon,dc=net?uid?sub?(objectclass=*)
In FreeIPA, all users are always listed under
cn=users,cn=accounts,dc=mydomain. This differs some other LDAP
systems (specifically Active Directory). This makes our search really
simple, as we can just pull every entity out of this base_dn and be
assured that all users will be able to log into OpenShift.
An Aside: Restricting Access
In this example, the LDAP URL is constructed so that all users can log in to OpenShift.
In many situations, there is a desire to lock this down to allow, for example, only users from a certain group to log in or other similar restriction.
While this is certainly possible, with the correct LDAP filter. I would posit that this is an anti-pattern, and that access control is much better co-ordinated via Groups and RBAC policies.
I have several reasons for this:
-
It’s imperative that the LDAP query returns quickly. This query is run every time a user logs in. If the query takes a long time to run, then the user experience will suffer.
-
Changing the
OAuthobject can potentially cause loss of service, especially if updated with incorrect values.
If you configure a very complicated query (especially if using nested group search on a complicated LDAP tree), then #1 is very possible.
And, secondly, if you specify a complicated query it increases the
chances of having to change the query in the future, which increases
the changes for mistakes when updating the OAuth object.
Therefore, my opinion is to let everyone log in. It’s a simple query and is unlikely to every change, unless there are massive change to the LDAP structure.
In that situation, controlling access is done via Groups and
Role-Based Access Control. This is easier to implement, less risky to
change, and much more flexible. A future blog post will cover this
topic in detaill.
attributes
When a user logs into OpenShift using an IdentityProvider, a set of
proxy Kubernetes object is created to represent that user. These
objects are used predominately in role based access control and group
membership, as well as in creation metadata for certain other objects.
The attributes field configures the IdentityProvider to map
attributes in the LDAP entity to fields in these proxy objects.
There are four attributes, let’s go over them quickly:
nameemailidpreferredUsername
name is a human readable name of the user. In Free IPA, this is in
the cn attribute of the LDAP entity.
email is, obviously, the user’s email address. In Free IPA, this is in
the mail attribute of the LDAP entity.
id is the most important of these attribute, as it is meant to map
to a LDAP field that uniquely identifies the user. As a consequence,
this attribute should never change during the life of the LDAP entity.
If it does change then the link between the user entity in LDAP and
the User object in OpenShift will be broken, and the user will no
longer be able to log in.
In Free IPA, the id attribute should be mapped to the dn attribute
of the LDAP entity.
preferredUsername is optional, but useful. By default, the
IdentityProvider will use id as the username for that user in
OpenShift. Unfortunately, dn is a big long, ugly LDAP Distinguished
Name, like this:
uid=cfh,cn=users,cn=accounts,dc=private,dc=opequon,dc=net.
preferredUsername, if specified, causes a different attribute to be
used for username. Generally, I want to use the same username as I
use for logging into Linux systems. In Free IPA, this is in the uid
attribute of the LDAP entity.
mappingMethod
When multiple IdentityProviders are configured in a single cluster,
then the mappingMethod is set to determine how username conflicts
are handled.
In the case where you only have one IdentityProvider configured,
then claim is the right value.
Putting it all together
Pre-requisites
Service Account
I need a read-only service account in my FreeIPA LDAP. This is not a regular user. I don’t want it to be able to log into any hosts or even the IPA console. I only want it to be able to do queries against FreeIPA’s LDAP.
To do this, create a LDAP System Account.
All these examples use the base domain of my system
(dc=private,dc=opequon,dc=net). You’ll obviously need to swap this
out with the specifics of your FreeIPA installation.
On the FreeIPA server:
[root@ipa ~]# ldapmodify -x -D 'cn=Directory Manager' -W
Enter LDAP Password:
# Paste in the below
dn: uid=openshift,cn=sysaccounts,cn=etc,dc=private,dc=opequon,dc=net <- CHANGE OPENSHIFT
changetype: add TO DESIRED NAME OF
objectclass: account SERVICE ACCOUNT
objectclass: simplesecurityobject
uid: openshift <- THIS SHOULD MATCH THE DN ABOVE
userPassword: changeMe <- THIS IS YOUR SERVICE ACCOUNT PASSWORD
passwordExpirationTime: 20380119031407Z <- 2038 EFFECTIVELY THE END OF TIME
nsIdleTimeout: 0
^D <- ACTUALLY TYPE Control-D
If successful, you should see the following output:
adding new entry "uid=openshift,cn=sysaccounts,cn=etc,dc=private,dc=opequon,dc=net"
You can then test this service account using a command similar to the following:
ldapsearch -x -D 'uid=openshift,cn=sysaccounts,cn=etc,dc=private,dc=opequon,dc=net' -W
This will spit out every object in the LDAP database. Of course you
can filter, see ldapsearch(1).
For both the ldapmodify and ldapsearch command, the arguments mean the following:
-x- use simple authentication (instead of a Kerberos ticket)-D- the distinguished name of the user-W- prompt for password
Certificate Authority
This file is normally found at /etc/ipa/ca.crt on any machine
connected to FreeIPA.
Grab this file, so it can put it into a config map later, or
alernatively run oc commands from a Linux machine that is connected
to FreeIPA.
OpenShift Configuration
Creating Secrets and ConfigMaps
The OAuth object we are creating requires a Secret for the LDAP
service account password.
This secret must be in the openshift-config Project, but can be
named anything so long as that name is used in the later OAuth
object.
To do so via the command line:
# oc project openshift-config
# oc create secret generic ldap-secret --from-literal=bindPassword=changeMe
This will create a Secret like the below. Alternatively, this
manifest can be applied directly using oc create, just be sure to
substitute the value of data.bindPassword with the Base64 encoded
string of your actual password.
apiVersion: v1
kind: Secret
metadata:
name: ldap-secret
namespace: openshift-config
type: Opaque
data:
bindPassword: Y2hhbmdlTWU=
In addition to the Secret, the FreeIPA certificate authority chain
must be in a ConfigMap object in the openshift-config namespace.
This file is normally found at /etc/ipa/ca.crt on any machine
connected to FreeIPA.
To create this ConfigMap via the command line:
oc project
oc create cm custom-ca-oauth --from-file=ca.crt=/etc/ipa/ca.crt -n openshift-config
Alternatively, this manifest can be applied directly using oc
create.
apiVersion: v1
kind: ConfigMap
metadata:
name: custom-ca-oauth
namespace: openshift-config
data:
ca.crt: |
-----BEGIN CERTIFICATE-----
REPLACE ME
-----END CERTIFICATE-----
Creating OAuth Object
With the LDAP service account created and the Secrets and
ConfigMaps in place, it’s time to create to update the OAuth object.
In OpenShift 4, an OAuth object will exist by default regardless of if
there are any IdentityProviders configured. We could use oc
replace to overwrite this object or just edit the object using either
oc edit or the web console.
Regardless of method chosen, the resulting object definition should look like this:
apiVersion: config.openshift.io/v1
kind: OAuth
metadata:
name: cluster
spec:
identityProviders:
- ldap:
attributes:
email:
- mail
id:
- dn
name:
- cn
preferredUsername:
- uid
bindDN: uid=openshift,cn=sysaccounts,cn=etc,dc=private,dc=opequon,dc=net
bindPassword:
name: ldap-secret # MUST MATCH OUR SECRET FOR LDAP
ca:
name: custom-ca-oauth # MUST MATCH OUR CA CONFIGMAP
insecure: false
url: ldaps://ipa.private.opequon.net/cn=users,cn=accounts,dc=private,dc=opequon,dc=net?uid
mappingMethod: claim
name: ldapidp
type: LDAP
bindDN and url must, of course, be updated to match your
environment. The names of the Secret and Certificate Authority
ConfigMap must match the names of those created in the previous
section.
Once this is applied, the authentication ClusterOperator will
apply the configuration you can check the status by looking at the
ClusterOperator objects (short name for these is co)
# oc get co authentication
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE
authentication 4.10.12 True False False 24h
While being configured, the PROGRESSING column will flip to false. This configuration should only take a few minutes to apply.
If it the DEGRADED column flips to true for a long period (or if
AVAILABLE becomes false), then use oc describe co authentication
to see events related to the problem.
Testing Logging in
After the authentication ClusterOperator applies the
configuration, on next log in attempt, the user will be presented with
an option to log in using FreeIPA as the provider. The name of this
provider is specified in the OAuth object
spec.identityprovider.ldap.name field. In our example, this is
ldapipa.
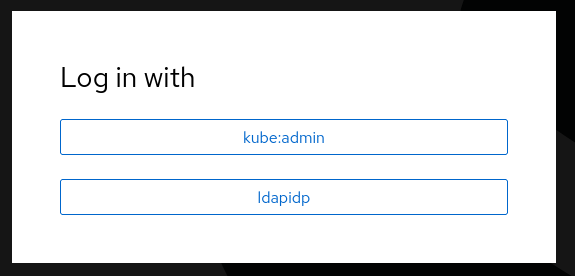
Once logged in, we should be able to see our User object.
# oc get users
NAME UID FULL NAME IDENTITIES
cfh 826d995a-2045-42dd-a4fa-81d338ebbefe Clark Hale ldapidp:dWlkPWNmaCxjbj11c2Vycyxjbj1hY2NvdW50cyxkYz1wcml2YXRlLGRjPW9wZXF1b24sZGM9bmV0
Additionally, we can see the Identity object
[root@meriadoc opequon_labs_ocp_playbooks]# oc get identity
NAME IDP NAME IDP USER NAME USER NAME USER UID
ldapidp:dWlkPWNmaCxjbj11c2Vycyxjbj1hY2NvdW50cyxkYz1wcml2YXRlLGRjPW9wZXF1b24sZGM9bmV0 ldapidp dWlkPWNmaCxjbj11c2Vycyxjbj1hY2NvdW50cyxkYz1wcml2YXRlLGRjPW9wZXF1b24sZGM9bmV0 cfh 826d995a-2045-42dd-a4fa-81d338ebbefe
We can see that these long strings are actually the value of the id
attribute, which we set to dn:
[root@meriadoc opequon_labs_ocp_playbooks]# echo "dWlkPWNmaCxjbj11c2Vycyxjbj1hY2NvdW50cyxkYz1wcml2YXRlLGRjPW9wZXF1b24sZGM9bmV0" | base64 -d
uid=cfh,cn=users,cn=accounts,dc=private,dc=opequon,dc=net
Next Steps
Now that users can log in, the next step is to synchronize groups from FreeIPA and then assigning Roles to those users.
- OpenShift Certificate from IPA on RHEL 8
- OpenShift authentication with IPA
- OpenShift Group Syncing with IPA (Not yet published)
- Automated Certificate Management with IPA and cert-manager (Not yet published)