Shell Magic: Set Operations with uniq
Update 2020: This was posted to
Hacker News where
there was some discussion on how this could be accomplished with the
comm command as well potentially more efficient ways to do this
with sort. It amazes me how flexible and expressive UNIX shell is
and how many different ways there are to accomplish things.
I don’t know of anyone else that does this, but it’s a neat little
trick for doing finding differences between lists as if they were
sets. This is extremely useful when, for example, you want to find a
list of things that are in list A, but not in list B. I’ve seen people
use diff(1), but it really is not the right tool for the job and
leads to some manual effort. uniq(1) is really the answer.
To start out with, I’ll have two lists, which are just normal files with one record per line:
$ more *
::::::::::::::
a_list
::::::::::::::
a
b
c
d
::::::::::::::
b_list
::::::::::::::
a
c
d
e
By sight we can tell that, a_list lacks ‘e’ but has ‘b’, and
b_list has ‘e’ but lacks ‘b’. This is easy for a small list, but for
a larger list, we’ll want to let the computer do it.
Before starting, it’s very important that lists are SORTED and
deduplicated! uniq(1) does not work on unsorted data and if there
are duplicate entries in the list, it cannot be treated as a set. My
example lists are already like this, but if yours are not it’s a
simple matter to clean them up and put them into a new file:
$ cat original_list | sort -u > original_list.sorted
Union – If I want the Union, that is all items that appear in either or both, of my two files:
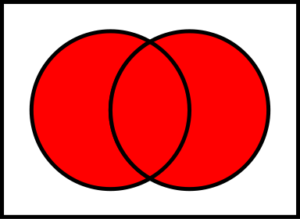
$ cat a_list b_list | sort | uniq
a
b
c
d
e
Intersection – If I want the Intersection, that is items that appear in only in both, of my two files:
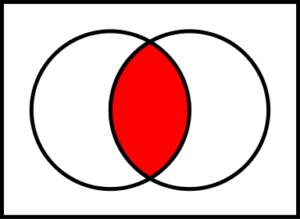
$ cat a_list b_list | sort | uniq -c
2 a
1 b
2 c
2 d
1 e
uniq -c will deduplicate an input and provide a count of the total
sum of duplicates for each line. Since we are concatenating two sets,
anything with a count of 2 is a member of both sets. If you have 3
files, then anything with a count of 3 and so on and so forth. Adding
a grep, we can very clearly get the intersection:
$ cat a_list b_list | sort | uniq -c | grep 2\
2 a
2 c
2 d
Lastly, Relative Complement AKA Set-Theoretic Difference – is used for when you want to find items that are only in one list.
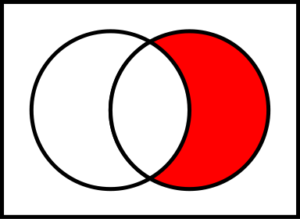
$ cat a_list b_list b_list | sort | uniq -c
3 a
1 b
3 c
3 d
2 e
Notice the command has b_list twice. This is to help with our set
difference. Since a_list and b_list are assumed to be sets
themselves, we can draw the following conclusions based on the counts:
- count = 3 present in both files
- count = 2 present in
b_listonly - count = 1 present in
a_listonly
We can add in a grep to only get those that we care about. For
example, if we wanted to see items that only exist in b_list:
$ cat a_list b_list b_list | sort | uniq -c | grep 2\
2 e
Unlike the intersection, the Set Difference is a bit harder to scale up to more than two lists. It is concievable, and I may even have done it, but I’ll leave it as an exercise to the reader to develop that.
Image Credits: Wikipedia